




Researchers at Microsoft announced VALL-E, a brand new text-to-speech AI model. The new tech is capable of closely stimulating a person’s voice with just three seconds of an audio sample.
What is VALL-E?
Microsoft’s VALL-E is capable of learning a specific voice with the help of a three-second-long audio recording. The AI model can synthesize audio based on the sample saying anything, in addition to preserving the emotional tone. Creators are speculating that the tech can be used for applications requiring high-quality text-to-speech. It can also be used in speech editing where a recording can be edited and changed based on a text transcript. Additionally, it can help in content creation when combined with generative AI tools such as ChatGPT.

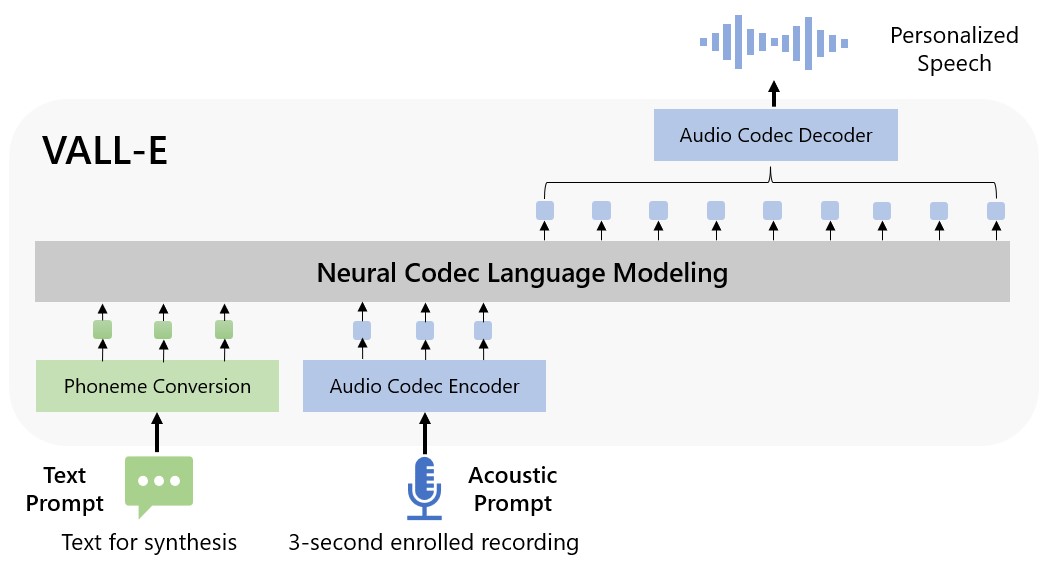
VALL-E is a “neural codec language model” and is based on EnCodecm first created by Meta in October 2022. Unlike existing text-to-speech models synthesizing speech by manipulation of waveforms, this uses discrete audio codec codes. This means it is capable of analyzing how a person sounds. Following this, it is capable of breaking it down into smaller tokens with the help of EnCodec. It then uses data for matching it with various samples to select the best match.
More on the text-to-speech generating AI tech
In addition to keeping the emotional tone and timbre of a speaker, VALL-E is also capable of imitating the “acoustic environment” of the sample. For example, if the sample audio was from a telephone call, the output will also contain the similarity. Hence sounding like the person is in a telephone conversation.
“Since VALL-E could synthesize speech that maintains speaker identity, it may carry potential risks in misuse of the model, such as spoofing voice identification or impersonating a specific speaker. To mitigate such risks, it is possible to build a detection model to discriminate whether an audio clip was synthesized by VALL-E. We will also put Microsoft AI Principles into practice when further developing the models,” stated the study conducted by the team.